
Mark Finkle suggested that I do some speed testing, now that a native implementation of getElementsByClassName has landed in the Mozilla trunk (destined for Firefox 3).
So I went around and dug up all of the different, existing, implementations that I could find. Currently, implementations fall into one of three categories (with some straddling more than one):
-
Pure DOM
This usually involves a calls to.getElementsByClassName("*")and traversing through all matched elements, analyzing each element’sclassNameattribute along the way. Generally, the fastest method is to use a pre-compiled RegExp to test the value of the className attribute. -
DOM Tree Walker
Is a less-popular means of traversing DOM documents by setting some simple parameters, as specified by the DOM Level 2 Spec. For example, you could traverse through all text nodes in a document (something that you can’t easily do in any other way). -
XPath
The most recent technique, to be popularized, was the use of XPath to find elements by classname. The implementation is generally simple: Building a single expressions and letting the XPath engine traverse through the document, finding all the relevant elements.
I’ve chosen some implementations that were representative of each of these techniques.
Tree Walker
An implementation using the DOM Level 2 Tree Walker methods. Builds a generic filter function and traverses through all elements.
document.getElementsByClass = function(needle) {
function acceptNode(node) {
if (node.hasAttribute("class")) {
var c = " " + node.className + " ";
if (c.indexOf(" " + needle + " ") != -1)
return NodeFilter.FILTER_ACCEPT;
}
return NodeFilter.FILTER_SKIP;
}
var treeWalker = document.createTreeWalker(document.documentElement,
NodeFilter.SHOW_ELEMENT, acceptNode, true);
var outArray = new Array();
if (treeWalker) {
var node = treeWalker.nextNode();
while (node) {
outArray.push(node);
node = treeWalker.nextNode();
}
}
return outArray;
}
The Ultimate getElementsByClassName
Uses a pure DOM implementation, tries to make some optimizations for Internet Explorer.
function getElementsByClassName(oElm, strTagName, strClassName){
var arrElements = (strTagName == "*" && oElm.all)? oElm.all :
oElm.getElementsByTagName(strTagName);
var arrReturnElements = new Array();
strClassName = strClassName.replace(/\-/g, "\\-");
var oRegExp = new RegExp("(^|\\s)" + strClassName + "(\\s|$)");
var oElement;
for(var i=0; i<arrElements.length; i++){
oElement = arrElements[i];
if(oRegExp.test(oElement.className)){
arrReturnElements.push(oElement);
}
}
return (arrReturnElements)
}
最新更新请点击这里,或者看附件。
Dustin Diaz’s getElementsByClass
A pure DOM implementation, caches the regexp, and is generally quite simple and easy to use.
It's simple. It works just how you think getElementsByClass would work, except better.
- Supply a class name as a string.
- (optional) Supply a node. This can be obtained by getElementById, or simply by just throwing in "document" (it will be document if don't supply a node)). It's mainly useful if you know your parent and you don't want to loop through the entire D.O.M.
- (optional) Limit your results by adding a tagName. Very useful when you're toggling checkboxes and etcetera. You could just supply "input". Or, if you're like me, and you said Good Bye to IE5, you can use the "*" asterisk as a catch-all (meaning 'any element).
function getElementsByClass(searchClass,node,tag) {
var classElements = new Array();
if ( node == null )
node = document;
if ( tag == null )
tag = '*';
var els = node.getElementsByTagName(tag);
var elsLen = els.length;
var pattern = new RegExp("(^|\\s)"+searchClass+"(\\s|$)");
for (i = 0, j = 0; i < elsLen; i++) {
if ( pattern.test(els[i].className) ) {
classElements[j] = els[i];
j++;
}
}
return classElements;
}
Prototype 1.5.0 (XPath)
Mixes an XPath and DOM implementation; using XPath wherever possible.
document.getElementsByClassName = function(className, parentElement) {
if (Prototype.BrowserFeatures.XPath) {
var q = ".//*[contains(concat(' ', @class, ' '), ' " + className + " ')]";
return document._getElementsByXPath(q, parentElement);
} else {
var children = ($(parentElement) || document.body).getElementsByTagName('*');
var elements = [], child;
for (var i = 0, length = children.length; i < length; i++) {
child = children[i];
if (Element.hasClassName(child, className))
elements.push(Element.extend(child));
}
return elements;
}
};
Native, Firefox 3
A native implementation, written in C++; is a part of the current CVS version of Firefox, will be included in Firefox 3.
document.getElementsByClassName
The Speed Results
For the speed tests I copied the Yahoo homepage into a single HTML file and used that as the test bed. They make good use of class names (both single and multiple) and is a considerably large file with lots of elements to consider.
You can find the test files, for each of the implementations, here:
http://ejohn.org/apps/classname/
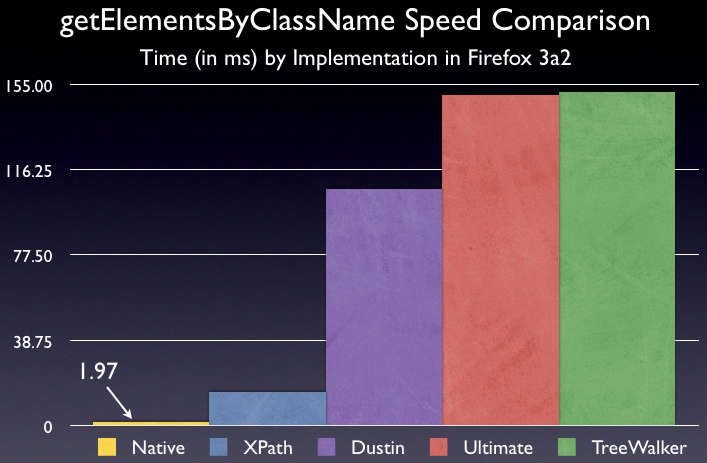
Note: “XPath” is just Prototype’s implementation.
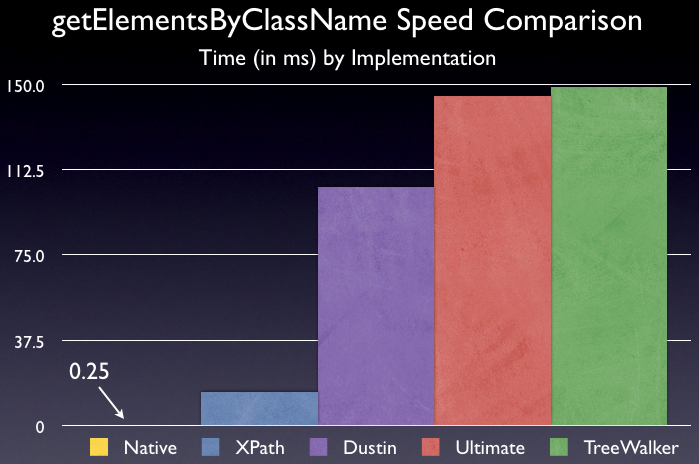
From these figures we can see that the native implementation of getElementsByClassName, in Firefox 3, is a full 8x faster than the XPath implementation. Additionally, it’s a stunning 77x faster than the fastest DOM implementation.
Note: These numbers have been revised from what was originally posted as the lazy-loading nature of
document.getElementsByClassNamewasn’t taken into account. The resulting arrays are completely looped-through now, making sure that all elements are accounted for.
Currently, Prototype has the best general-use implementation: Use XPath selectors wherever possible, fall back to fast DOM parsing.
Interestingly, only Prototype actually tries to implement the document.getElementsByClassName interface (all others do one-off names). However, Prototype doesn’t check to see if the document.getElementsByClassName property already exists, and completely overwrites the, incredibly fast, native implementation that Firefox 3 provides (oops!).
In all, the results are quite astounding. The native implementation is absolutely much faster than anything I could’ve imagined. It completely decimates all the other pieces of code. I can’t wait until this hits the general public – users will, absolutely, feel a significant increase in speed.



{kind=link}
相关推荐
javascript通过className获取文件元素.docx
本篇文章主要是对javascript通过className来获取元素的简单示例代码进行了介绍,需要的朋友可以过来参考下,希望对大家有所帮助
下面小编就为大家带来一篇js通过classname来获取元素的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起 小编过来看看吧
主要介绍了JS封装通过className获取元素的函数,涉及javascript针对页面元素属性的遍历与数组相关操作技巧,需要的朋友可以参考下
js 获取class的元素的方法 以及创建方法getElementsByClassName,需要的朋友可以参考一下
代码如下: function getByClass(classname){ var nodes = document.getElementsByTagName(‘*’), ret=[]; for(var i=0;i<nodes.length;i++){ if(hasClass(nodes[i],classname)) ret.push(nodes[i]); } return ...
getElementsByClassName() 为了从一大堆HTML代码中找出我们的树状菜单(也许有多个),我们先来实现一个通过className找DOM节点的方法:getElementsByClassName。这是对浏览器自有DOM方法的一个简单但实用的扩充。 此...
代码如下: function getElementsByClassName(n) { var classElements = [],allElements = document.getElementsByTagName(‘*’); for (var i=0; i< allElements.length; i++ ) { if (allElements[i].className =...
先来看一下代码:(支持多个class查询和在某个范围内进行查询) 代码如下: /* * 根据元素clsssName得到元素集合 * @param fatherId 父元素的ID,默认为document * @tagName 子元素的标签名 * @className 用空格分开...
B 使用className 属性 Javascript 还可以通过className 属性灵活的更改一个标签元素的CSS 类选择器来实现样式的变化。 代码示例: 代码如下: <html> <head> <title>追加CSS类别</title
整理的10大JavaScript函数,prototype的$函数,隐藏、显示元素函数,通过className获取DOM元素函数
2. 为网页内的某个元素指定一个css样式来更改该元素的外观 <!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <title>className...
React类名允许使用指定 className 的纯字符串创建元素目的支持在没有 JSX 的情况下使用 React - 这是一个有趣的库的不幸污点。 使用此模块,您可以非常简洁地呈现只有className结构元素(比 JSX 更是如此)。安装 ...
第1章 JavaScript简介 1 1.1 JavaScript是什么 1 1.2 JavaScript不是什么 2 1.3 JavaScript的用处 3 1.4 JavaScript及其在Web页面中的位置 3 1.5 Ajax是什么 5 1.6 JavaScript是什么样子的 6 1.7 ...
本文实例讲述了JavaScript实现获取dom中class的方法。分享给大家供大家参考。具体实现方法如下: <!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></...
安装npm: npm install classname 或者只是在浏览器中加载classname.js ,然后直接调用它。文档 classname ( 1 , 'one' , false , 'two' ) ; // '1 one two'classname ( { one : true , two : false , three : true} ...